Introduction
This site presents a structured set of concepts and strategies for optimizing sequential performance in modern systems. It is a restructured and accessible version of the ideas presented in the paper “Principles and Methodologies for Serial Performance Optimization (OSDI’25)”.
The content is intended to serve as a reference and guide, helping system designers and engineers identify opportunities for improving latency and throughput when facing performance bottlenecks, especially in the parts of the system that cannot be parallelized.
Why Sequential Performance?
Improving performance has long been a core challenge in system design. Even with continued progress in parallel computing, many critical bottlenecks arise from sequential execution, where code must run in a specific order and cannot be parallelized due to logical or data dependencies.
According to Amdahl’s Law, the portion of a system that remains sequential limits the maximum achievable speedup. So, even in highly parallel systems, improving sequential performance is essential for making meaningful overall gains.
A Structured Approach
To make sequential performance optimization more systematic, this guide introduces three foundational principles:
- Removal – Eliminate unnecessary tasks.
- Replacement – Substitute with faster alternatives.
- Reordering – Execute tasks in a more efficient sequence.
These principles are the basis for eight actionable methodologies that appear again and again in systems research and practice:
- Batching
- Caching
- Precomputing
- Deferring
- Relaxation
- Contextualization
- Hardware Specialization
- Layering
More Than Theory
Each methodology in this guide is explained through clear examples, diagrams, and patterns found in real systems. The goal is not only to provide insight, but also to serve as a checklist and design vocabulary that helps you:
- Understand where inefficiencies come from
- Apply proven optimization strategies
- Discover new directions for improving throughput and latency
To bridge theory and application, the final section introduces SysGPT, a language model fine-tuned to suggest system performance improvements using this exact methodology.
Serial Performance
Performance optimization in system design often centers around making things faster or more scalable. While parallelism plays a major role in this, one critical limitation remains: some parts of the system simply cannot be parallelized.
These sequential sections limit overall performance, even in systems with many cores or distributed architecture.
Why Sequential Performance Matters
These sequential components—the portions of execution that must occur in a fixed order—have a disproportionate impact on overall performance.
The fundamental reason is captured by Amdahl’s Law, which states that the maximum speedup of a program is limited by the fraction that must be executed sequentially.
- : the maximum speedup with processors
- : the fraction of the workload that is sequential
- : the fraction that can be parallelized
Even with an infinite number of processors, the sequential portion becomes the limiting factor. In real-world systems, sequential work is common in areas like I/O, memory management, synchronization, and task scheduling. This is why reducing the cost of sequential execution is critical, especially in systems where parallelism cannot be fully exploited.
Modeling Serial Execution
To reason about serial performance more clearly, we define the work as a sequence of tasks:
- : a sequence of tasks to be executed in order
- : an individual task
This sequence models one logical unit of work, commonly referred to as an epoch. Many systems repeatedly execute similar task sequences—such as request handling loops, model training steps, or update cycles—and optimizing these repeated patterns is often the most effective path to performance gains.
Each task contributes directly to the overall runtime of the epoch. Therefore, the cost of processing the sequence, denoted by , is deterministically influenced by both the content and order of the sequence , as well as by the underlying hardware on which it runs. This deterministic nature makes it possible to reason precisely about optimizations and their effects.
Latency and Throughput
This model allows us to represent two central performance metrics:
Latency
The time required to complete a single epoch:
Where is the total execution time of the sequence.
Throughput
The number of epochs that can be completed within a given time:
Here, is a fixed time budget (e.g. 1 second), and is the number of full epochs that can be completed.
These definitions provide a simple but powerful model for thinking about serial performance. The remainder of this guide focuses on how to optimize using structured and feasible strategies.
The Three Principles of Sequential Optimization
When working with sequential code, performance improvements must come from altering the sequence of tasks itself. Unlike parallel execution, where independent tasks can be distributed, sequential code has a strict order and dependency. As a result, optimization is fundamentally constrained.
This guide introduces three core principles for improving sequential performance. All practical optimization techniques can be understood as combinations or variations of these principles.
1. Removal
Definition: Eliminate unnecessary tasks from the sequence.
If a task does not contribute to correctness or output, removing it reduces the total length and cost of the sequence:
- The new sequence becomes shorter than the original , where .
This is the most direct form of optimization. Redundant computations, logging, duplicate checks, or stale operations are often good candidates for removal.
2. Replacement
Definition: Replace an existing task with a faster or simpler alternative.
Instead of removing a task entirely, it may be possible to replace it with another that achieves the same purpose more efficiently:
- becomes
- , even though the sequence length remains the same
Common examples include algorithm substitution, approximate computation, or context-aware decisions.
3. Reordering
Definition: Explore alternative permutations of .
Task order affects memory access patterns, data locality, and hardware efficiency. By reordering tasks carefully, systems can improve cache utilization, lock contention, I/O scheduling, or task pipelining.
The goal is to find , a permutation of that leads to lower total cost:
Why These Three?
Sequential performance is deterministic: the total runtime depends directly on the tasks, their order, and the hardware. Without changing the system’s algorithm or correctness, removal, replacement, and reordering are the only general-purpose levers available.
All of the optimization methodologies discussed in this guide — such as batching, caching, or deferring — are built from combinations of these principles.
In the next section, we define these eight methodologies in detail and show how each one aligns with these foundational ideas.
The Eight Optimization Methodologies
While sequential performance optimization often appears open-ended or intuition-driven, it can actually be explained using a small set of recurring strategies.
This guide defines eight core methodologies, each grounded in the principles of removal, replacement, and reordering introduced earlier.
These methodologies have emerged from analyzing hundreds of real system papers and implementations. They cover the most common and effective patterns used to reduce latency and improve throughput in sequential execution.
Overview
Each methodology provides a different way to reduce the cost of sequential task sequences. They are often used in combination, and many real systems apply multiple strategies at once.
Click on any item to explore details, examples, and design conditions.
- Batching: Combine similar or repeated operations into larger units to reduce overhead.
- Caching: Store and reuse the results of expensive computations to avoid recomputation.
- Precomputing: Execute certain tasks ahead of time, outside the critical path.
- Deferring: Delay non-essential tasks until a more favorable time.
- Relaxation: Trade accuracy, consistency, or durability for performance gains.
- Contextualization: Use runtime information to make decisions more tailored and efficient.
- Hardware Specialization: Leverage specialized hardware to reduce task cost.
- Layering: Restructure or bypass software layers to remove unnecessary overhead.
Each of the following sections covers:
- What the methodology does
- How it relates to the three principles
- Conditions and caveats for applying it
- Real-world examples from systems research
Together, these form a practical vocabulary for designing or analyzing performance optimizations in modern systems.
Batching
Batching is a technique that combines multiple tasks into a single grouped operation. Instead of processing each task individually, the system handles them together, reducing duplicated overhead and improving resource efficiency.
This is one of the most widely used methods in performance-critical systems, as it directly reduces the number of operations executed and enables further optimizations like deferring, caching, and reordering.
1. Definition with Visual Example
Batching replaces multiple individual operations with a single composite task. Below is a visual example of how batching transforms a task sequence.
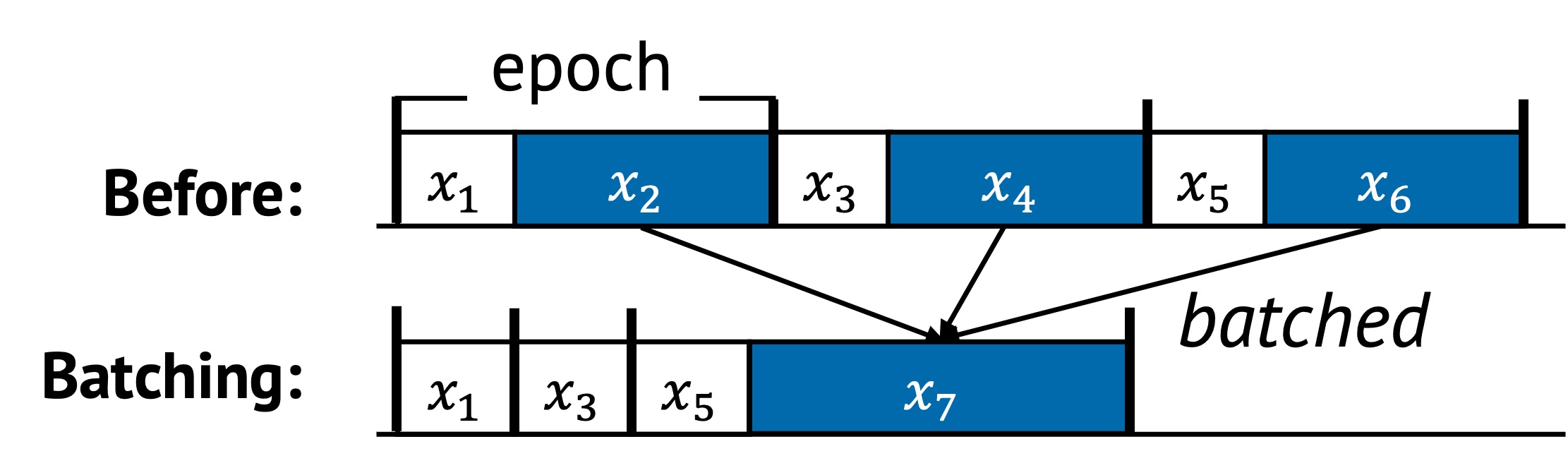
In the original sequence:
- Tasks , , and are repeated across epochs
- These incur repeated costs during each iteration
After batching:
- Redundant steps are merged into a new task
- The sequence becomes shorter and more efficient
- Tasks , , and are removed or replaced
2. Underlying Principles
Batching leverages all three core principles of sequential optimization:
- Removal: Discards duplicated or redundant tasks such as stale writes or repeated validations
- Replacement: Combines tasks into one (e.g., replacing multiple flushes with a single commit)
- Reordering: Alters task order to group similar operations together and improve data locality
These effects often happen simultaneously during batching, making it a powerful and multidimensional technique.
3. Conditions for Batching
Batching is beneficial when the following condition holds:
This means:
- The batched sequence has fewer tasks
- The combined runtime of the individual tasks is greater than the cost of the batch operation
4. When to Apply
Batching is effective in several scenarios:
Coalesced Calls
This is common when each individual call is expensive due to fixed setup or context-switching costs. In such cases, batching provides an opportunity to amortize that cost over multiple tasks.
For example, a Direct Memory Access (DMA) operation has a fixed setup cost and a per-byte transfer cost. If each DMA is invoked separately, the fixed overhead is paid every time. But by batching multiple DMAs into one large operation, the setup cost is incurred only once.
This concept generalizes to many other operations:
- Remote Procedure Calls (RPCs)
- System calls
- GPU kernel launches
- Disk I/O flushes
- Network packet transmission
All of these benefit from batching when there’s non-trivial per-task overhead. Without batching, this cost is redundantly paid in every epoch or iteration. With batching, the system executes a combined operation that eliminates repeated overhead and improves throughput.
Discard Stale Tasks at the Time of Batched Request
In many systems, updates to state happen rapidly and repeatedly. When batching is applied, some operations may become unnecessary by the time the batch is processed.
This allows the system to skip redundant work.
For example, a write buffer may receive multiple writes to the same file block. By the time the batch is flushed to disk, only the most recent update needs to be committed — earlier writes can be discarded.
This behavior leads to two benefits:
- Reduces wasted I/O or CPU cycles
- Shortens the effective task sequence by applying removal
It’s especially valuable in scenarios where tasks invalidate or overwrite each other within short time spans, such as key-value store updates or configuration writes.
Improve Spatial and Temporal Locality
Batching naturally groups related tasks. This reordering effect improves how data is accessed in memory or on hardware queues.
For example:
- Reading or writing adjacent memory addresses can reduce cache misses.
- Grouping I/O by file block or sector reduces seek and write amplification.
- Batching packets in a network stack improves CPU cache and queue efficiency.
Even when tasks aren’t logically related, reordering them through batching can uncover new locality opportunities the original sequence could not take advantage of.
5. Examples from Real Systems
| System | Description |
|---|---|
| NEVE (SOSP’17) | Coalesce and defer traps to the hypervisor by logging to avoid context switch overhead between a VM and the hypervisor. |
| EAW (SOSP’13) | Exclude outdated data from the batch by allowing modifications in the log before committin. |
| IX (OSDI’14) | Apply batching at every stage of the network stack, including system calls and hardware queues to enhance instruction and data locality. |
Additional Notes
- Batching is often closely tied to deferring. Tasks are delayed until a batch threshold is reached.
- Batching often enables better caching, by grouping operations accessing similar memory regions.
- Batching increase latency for the first tasks in a batch, so it’s important to balance throughput with responsiveness.
Up next: Caching →
Caching
Caching is a technique that stores the result of a previously completed task, so that it can be reused when the same computation or data access is needed again. Instead of repeating work, the system retrieves a saved result, thereby reducing runtime and redundant effort.
While batching eliminates repeated work across tasks in the same epoch, caching focuses on redundant work across time—reusing results across multiple epochs, requests, or executions.
1. Definition with Visual Example
Caching replaces repeated computation or access with a cheaper lookup task.
For example:
- Without caching, computing a result (e.g., permission checks, network routing) happens every time.
- With caching, the result is stored and reused if the input or access pattern matches.
Caching is particularly effective when the same task appears repeatedly in sequential execution, especially across multiple epochs.
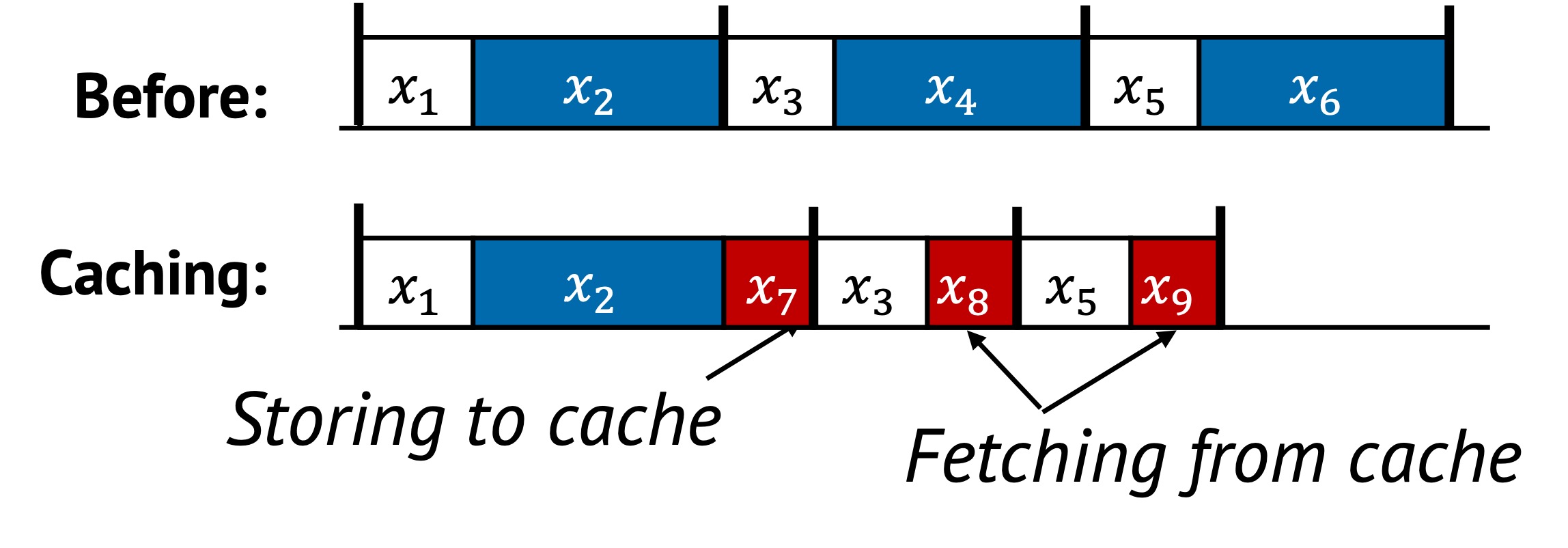
In this example:
- The original execution repeats , , and every epoch.
- Caching first executes and stores its result as . This represents the additional cost of caching (e.g., writing to memory).
- Later, instead of re-computing and , the system performs simple lookups, represented as and .
- These lookups are significantly cheaper than the original computations.
By avoiding full re-execution of and , caching saves total runtime across epochs—as long as the caching overhead (, , ) is less than the cost of the original tasks.
2. Underlying Principles
Caching primarily applies the replacement principle by substituting repeated computations with cheaper lookups.
3. Conditions for Effective Caching
Caching is effective when:
Where:
- , are original task costs
- is the cost to populate the cache
- , are the cost of retrieving cached results
Caching should only be used when:
- The overhead of maintaining the cache is less than the cost of repeated computation
- There is a high chance of reuse (temporal locality)
4. When to Apply
From our analysis, we observed three common ways caching is applied in real systems. These reflect where and how caching is introduced to maximize reuse and reduce redundant computation.
1. Introducing a New Caching Layer
This is the most straightforward approach. A caching layer is added on top of an existing system or component to intercept expensive operations. For example, adding a read cache to a file system improves performance by avoiding repeated disk reads.
This technique works well when:
- The system’s logic is stable and cacheable
- Repeated accesses happen at a higher layer (e.g., middleware, clients)
By layering caching externally, performance improves without modifying core logic.
2. Modifying the System to Expose Reuse
Sometimes, caching opportunities are hidden because the system’s structure doesn’t separate reusable computations from non-reusable ones. In these cases, modifying the internal logic can make reuse more explicit and accessible.
For example, decoupling permission checks from directory lookups1 allows the system to cache the result of permission validation independently, even if the path structure changes. Similarly, separating expensive parsing from request routing enables selective caching of parsed metadata.
This approach requires changes to internal components, but it often leads to finer-grained reuse and better cache hit rates — especially in low-level systems where performance is critical.
3. Designing a Cache Policy
Even with caching in place, performance depends heavily on choosing what to cache and when. A well-designed cache policy maximizes benefit while minimizing memory usage and consistency risk.
For example, an LRU (Least Recently Used) policy retains the most frequently accessed data, which works well in systems with temporal locality. In key-value stores, selectively caching hot keys based on access frequency improves lookup latency.
Effective policies often adapt to workload patterns, dynamically adjusting what is kept in cache and what is evicted, making the difference between helpful and harmful caching.
These three strategies—layering, refactoring, and policy—represent the most common ways caching is adopted and optimized in real systems. Many implementations combine them, starting with a layer and then refining reuse and policies over time.
5. Examples from Real Systems
| System | Description |
|---|---|
| Drizzle (SOSP’17) | Reuse scheduling decisions across micro-batches as computation is largely static and undergoes infrequent changes. |
| Protean (OSDI’20) | Cache previous virtual machine allocation result and reuse the placement across multiple requests. |
| Tasi et al. (SOSP’15) | Decouple permission checking from locating a directory and memoizes permission check resuls to enable fast path. |
| NetCache (SOSP’17) | Uses programmable switches to cache hot items in the network dataplane, reducing latency in key-value lookups. |
Additional Notes
- Caching is sometimes layered: intermediate layers cache partial results, upper layers cache full responses.
- Managing cache consistency is crucial. Stale or invalid entries can lead to incorrect behavior.
- Eviction policy (e.g., LRU, LFU, TTL) plays a key role in keeping the cache useful and efficient.
Up next: Precomputing →
-
Chia-Che Tsai, Yang Zhan, Jayashree Reddy, Yizheng Jiao, Tao Zhang, and Donald E. Porter. 2015. How to get more value from your file system directory cache. In Proceedings of the 25th Symposium on Operating Systems Principles (SOSP ’15). Association for Computing Machinery, New York, NY, USA, 441–456. https://doi.org/10.1145/2815400.2815405 ↩
Precomputing
Precomputing is a technique where certain tasks are executed before they are strictly needed. By moving work earlier in time, the system can reduce latency during performance-critical execution paths.
Instead of waiting until a task is required at runtime, the system anticipates that it will be needed and performs it in advance. This reduces the workload during peak times and allows smoother execution when the result is actually used.
1. Definition with Visual Example
Precomputing involves moving tasks earlier in time to reduce their runtime impact. There are two common forms:
- Moving tasks completely outside the sequence (to eliminate their cost from the critical path)
- Reordering tasks within the sequence (to improve locality or overlap with other work)
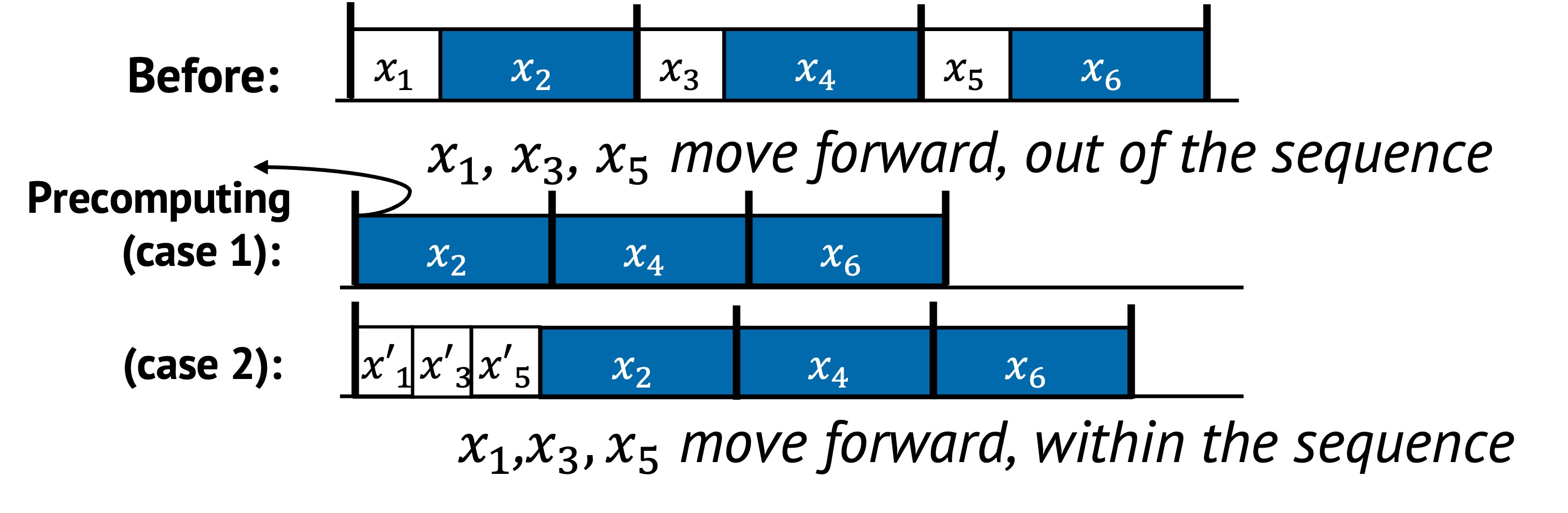
In the figure above:
- In the second row, tasks , , and are precomputed before the epoch starts. These are executed ahead of time, and do not block the main path anymore. This reduces critical path length by removing predictable work.
- In the third row, , , and are moved earlier within the sequence and replaced with , , and . These earlier positions allow the system to better exploit data locality or reduce contention (e.g., loading data while the system is otherwise idle).
Both techniques reduce the perceived latency of the epoch. The first strategy focuses on eliminating runtime cost, while the second aims to improve execution efficiency by changing timing within the same sequence.
2. Underlying Principles
Precomputing primarily uses the following principles:
- Removal: Tasks are taken off the critical path and handled in advance
- Reordering: Task execution is shifted to an earlier point in time
3. Conditions for Precomputing
Precomputing is effective under the following conditions:
This means either:
- Moving tasks out of the sequence reduces the total number of tasks
- Reordering tasks leads to more efficient execution
Additionally, the system must have:
- Tasks can be safely and meaningfully predicted
- Idle or underutilized resources are available
- The cost of early execution is lower than doing it on-demand
4. When to Apply
There are three common strategies for precomputing in practice:
Moving Tasks Out of the Sequence
Some tasks can be safely executed before the main sequence begins. This is especially useful when the system is idle or under low load.
For example, memory managers may begin garbage collection in advance when memory pressure starts rising, rather than waiting until it reaches a critical threshold.
Reordering Within the Sequence
Other tasks benefit from being shifted earlier within the same sequence. Reordering may help align with existing data in cache or reduce contention with nearby operations.
For example, reading a hot object earlier in the pipeline can warm the cache and reduce future misses.
Speculation
Both strategies depend on some form of speculation.
- Future need prediction: The system guesses a task will be needed soon
- Sufficient context assumption: The system assumes that current information is sufficient to perform useful computation ahead of time
When correct, speculation saves time without adding risk. When wrong, the system may need to re-execute or fall back to a slow path.
5. Examples from Real Systems
| System | Description |
|---|---|
| Duet (SOSP’15) | Reorder storage maintenance to prioritize data already cached in memory. |
| Itasks (SOSP’15) | Proactively trigger memory reclaiming upon detecting the first sign of memory pressure to reduce garbage collection during critical path. |
| Correctables (OSDI’16) | Prefetch dependent objects based on preliminary view instead of waiting for fully consistent one to hide the latency of strong consistency. |
Additional Notes
- Precomputing is often used together with caching and relaxation. The system computes results early and stores them for future reuse, as in caching. At the same time, it may need to tolerate partial, outdated, or approximate results—this trade-off aligns with relaxation. For example, speculative prefetching or early object construction may proceed with incomplete information, accepting that the result may not be perfect but still useful.
- It works best when prediction is accurate and the cost of being wrong is low
- In systems with tight correctness requirements, fallback logic may be needed to handle mispredictions
Up next: Deferring →
Deferring
Deferring is a technique where tasks are intentionally postponed to a later time. Unlike precomputing, which executes work early, deferring takes the opposite approach: it delays execution to reduce contention on the performance-critical path or to wait for more favorable conditions.
1. Definition with Visual Example
Deferring typically applies in two forms:
- Moving tasks out of the sequence, so they are executed after the main critical path is finished
- Reordering tasks later within the sequence, allowing the system to delay work until it becomes cheaper or more informed
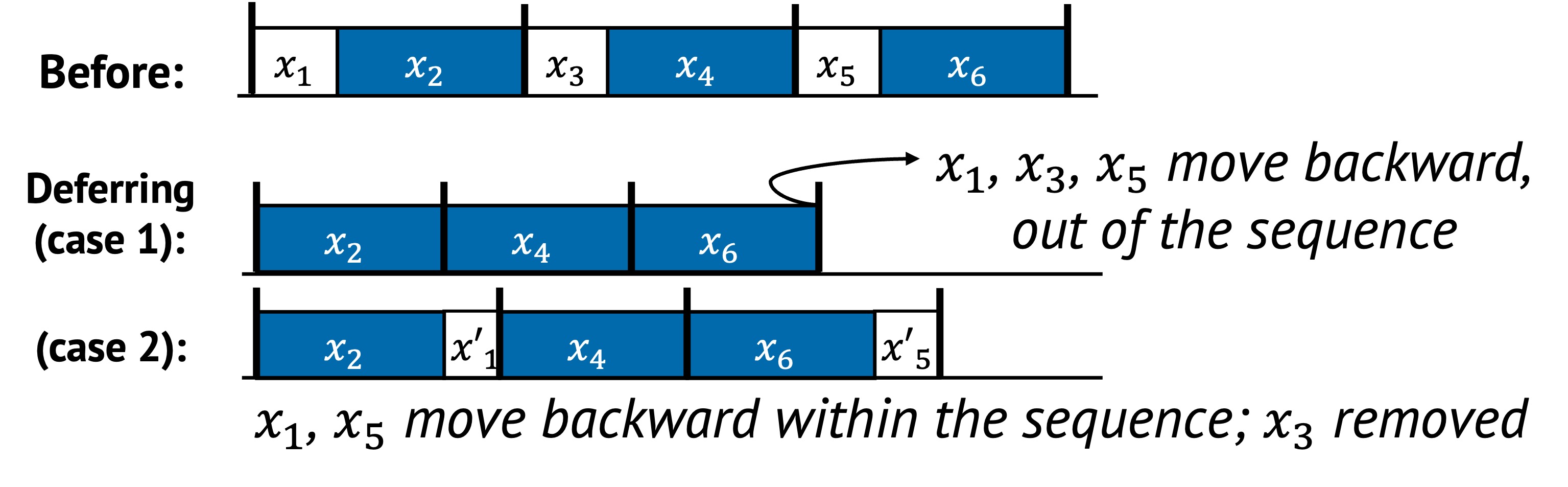
In the figure above:
- In the second row, , , and are completely deferred and removed from the critical path (). The remaining sequence becomes shorter and faster to execute.
- In the third row, those same tasks are deferred within the sequence and become and , indicating they are executed later when they may be cheaper, better informed, or even unnecessary ().
Both forms reduce the immediate workload in and allow the system to prioritize latency-sensitive execution.
2. Underlying Principles
Deferring primarily uses:
- Removal: Tasks are taken out of the performance-critical sequence
- Reordering: Tasks are delayed within the sequence to a more favorable point
Unlike precomputing, which speculates early usefulness, deferring speculates that later execution will be cheaper, smarter, or possibly avoidable.
3. Conditions for Deferring
Deferring is effective when:
- A task is not immediately required to preserve correctness
- Postponement leads to more efficient execution or more informed decisions
- There is a chance the task will become unnecessary
A common condition is:
This means deferring to after leads to a better overall runtime.
4. When to Apply
We identify three typical strategies for applying deferring in real systems.
Prioritize the Performance-Sensitive Sequence
In some cases, tasks are delayed simply to avoid slowing down the main path. They are deferred to execute lazily after the critical sequence is finished, even if that means sacrificing some responsiveness later.
For example, a system may delay data durability checks or index updates until after the user-visible response is sent. This prioritizes fast response at the cost of later performance.
Wait for Better Information
Deferring can be beneficial when a task can make a better decision later, with more complete or up-to-date context.
For example, a scheduler might defer assigning a task to a worker until more information about resource availability is available. This leads to better placement decisions and reduces the chance of needing to undo or reassign work.
Skip Work That May Become Unnecessary
Sometimes, a task may turn out to be irrelevant or unnecessary. Deferring gives the system a chance to observe whether the task still matters later — and skip it entirely if not.
For example, optimistic concurrency control defers the cost of managing locks until the moment a conflict actually occurs. This lazy approach assumes most transactions will not conflict and avoids lock overhead unless truly required. If no conflict arises, the system skips the entire concurrency resolution step, saving work.
5. Examples from Real Systems
| System | Description |
|---|---|
| Sparrow (SOSP’13) | Delay assignment of tasks to worker machine until workers are prepared, mitigating race conditions among multiple distributed schedulers. |
| PACTree (SOSP’21) | With optimistic version lock, perform an operation optimistically without holding a lock and then check the version number. |
| SKYROS (SOSP’21) | Defer expensive ordering and operation execution until their effects are externalized. |
Additional Notes
- Deferring is often paired with batching, since delayed tasks can be grouped and handled more efficiently later
- It reduces pressure on the critical path but can increase tail latency if not carefully managed
Up next: Relaxation →
Relaxation
Relaxation is a technique that improves performance by relaxing certain non-functional properties of a system. Instead of strictly preserving correctness guarantees like accuracy, consistency, or durability, the system chooses to weaken these guarantees in exchange for better speed, lower latency, or increased throughput.
Relaxation is especially powerful when exact correctness is not critical, or when approximate answers are good enough for the task at hand.
1. Definition with Visual Example
In relaxation, some tasks are either replaced with lighter versions or skipped entirely. This reduces the cost of execution, sometimes significantly, while still delivering acceptable results.
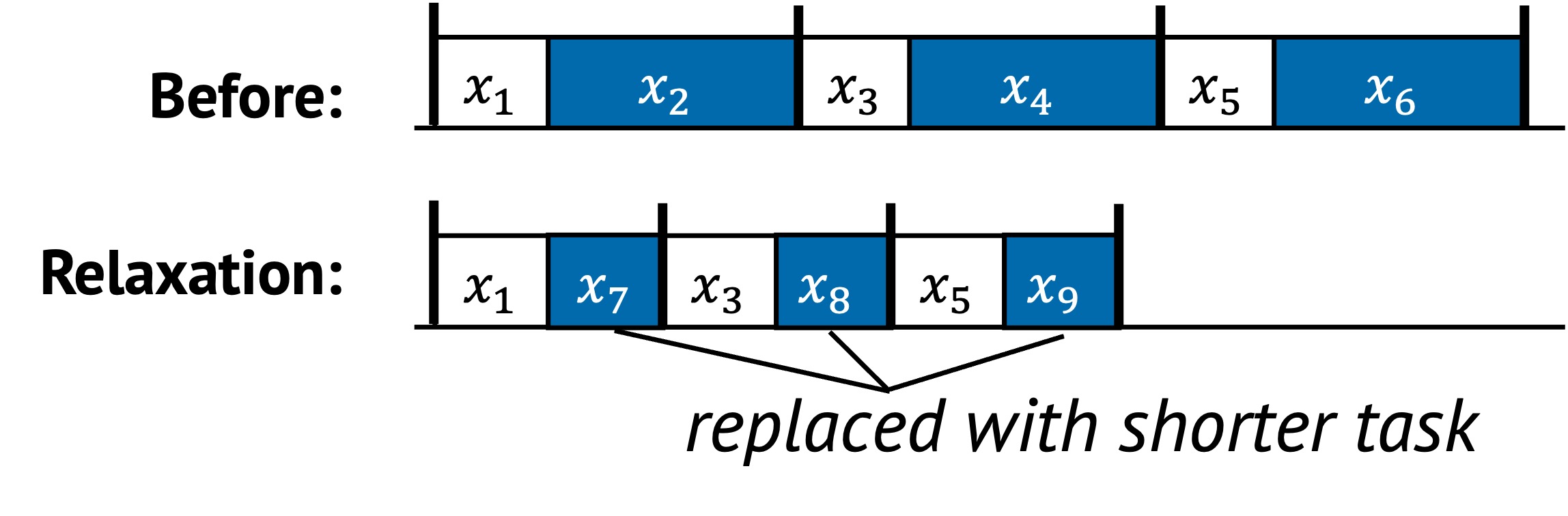
In the example above:
- Tasks , , and are replaced with approximate versions , , and
- These approximations are faster and less resource-intensive
- The full sequence becomes more efficient, but possibly less precise
The trade-off here is between performance and non-functional guarantees like precision or reliability.
2. Underlying Principles
Relaxation applies two principles:
- Replacement: Swap heavy or strict tasks with lighter or weaker versions
- Removal: Skip tasks that enforce strict properties, when they are not strictly needed
3. Conditions for Relaxation
Relaxation is effective when:
- The system can tolerate approximation, staleness, or reduced guarantees
- Performance bottlenecks come from enforcement of strict policies
- The trade-off does not significantly harm user experience or application correctness
The common condition is:
This means the relaxed version performs the same task more cheaply, even if it sacrifices some property.
4. When to Apply
There are three typical scenarios where relaxation is used.
Approximate Results Are Acceptable
In some domains, full accuracy is not necessary. Relaxed versions of a task can return approximate but usable results faster. For example, sampling-based analytics compute estimates over a small subset of data instead of scanning everything. This speeds up processing while keeping the result statistically meaningful.
In AI-serving systems, similar trade-offs are common. Some frameworks allow non-deterministic scheduling or reuse of stale or approximate results to improve throughput, even if outputs are not exactly reproducible.
Consistency Can Be Loosened
Relaxation often targets consistency guarantees in distributed systems. For example, a system may serve slightly stale data to reduce the cost of coordination. Causal consistency or eventual consistency is used instead of strong consistency to avoid blocking or waiting for global agreement. This can significantly reduce latency in read-heavy workloads.
Other Strong Guarantees Can Be Relaxed
Relaxation is often applied to core system guarantees such as strict serializability, linearizability, durability, or availability. By partially loosening these properties, systems can reduce coordination overhead, lower latency, or increase throughput.
For example:
- A system may delay durability by buffering writes in memory, deferring persistence to improve performance.
- Strict serializability may be relaxed to allow operations to complete locally without blocking for global order.
- Availability can be prioritized by serving stale or approximate results when the most up-to-date state is unreachable.
These relaxations come with trade-offs in correctness or failure semantics, but are widely used in real-world systems when the performance benefits justify them.
5. Examples from Real Systems
| System | Description |
|---|---|
| KnightKing (SOSP’19) | Allow for sampling the next edge in random walk algorithms without scanning all out-edges at the walker’s current vertex. |
| RSS and RSC (SOSP’21) | Relax certain real-time guarantees of strict serializability for causally unrelated transactions or operations. |
| SAUCR (OSDI’18) | Relax durability and availability when most servers crash simultaneously to achieve performance comparable to memory-durable one. |
Additional Notes
- Relaxation must be carefully scoped to avoid violating application correctness
Up next: Contextualization →
Contextualization
Contextualization is a performance technique where the system adapts its behavior based on current runtime conditions. Instead of using the same fixed plan every time, the system observes its environment and decides how to execute based on what it sees. This enables more efficient execution by avoiding unnecessary work or choosing better strategies for each situation.
1. Definition with Visual Example
Contextualization changes execution paths based on observed workload, input pattern, or system state. The system may skip tasks, reorder them, or replace them depending on the available context.
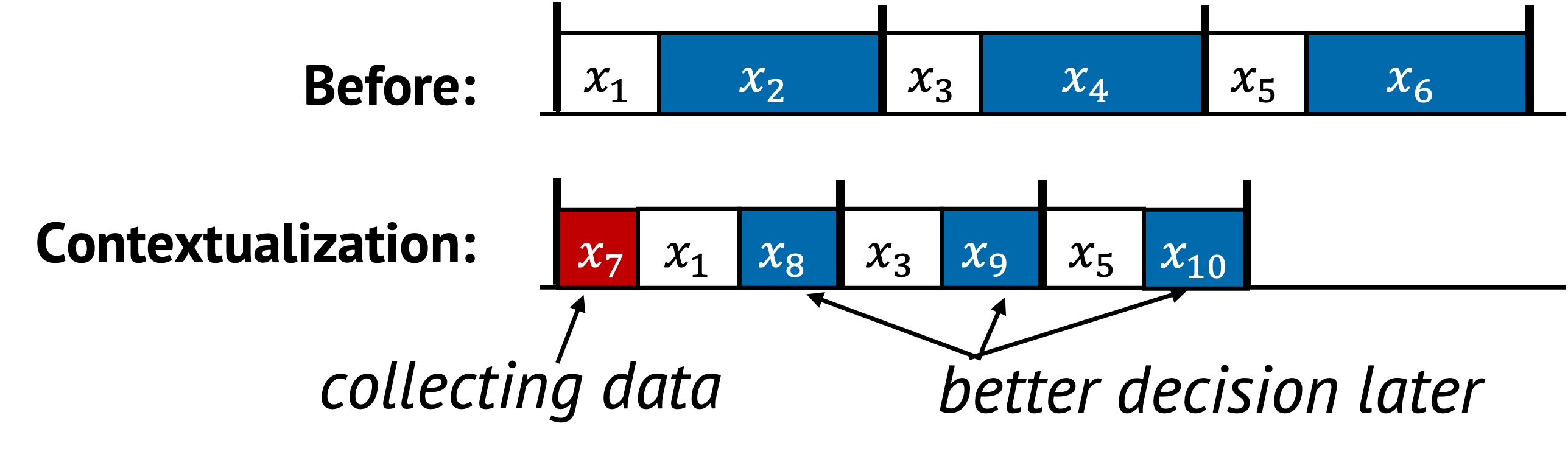
In the original sequence, tasks from to are executed the same way in every epoch. After contextualization, a new decision point is introduced. This task observes the current context and triggers a modified execution plan:
- Some tasks such as , , and are replaced by , , and
- Other tasks like , , and are reused as-is
This adaptation is based on runtime conditions. Each execution may follow a different path depending on what learns. This enables the system to run faster under certain inputs or load patterns without sacrificing correctness.
2. Underlying Principles
Contextualization applies:
- Replacement: A more efficient version of a task is selected based on current conditions
This dynamic adjustment makes the system more flexible and efficient than a fixed strategy.
3. Conditions for Contextualization
Contextualization is useful when:
- The system handles diverse inputs or workloads
- Different runtime conditions lead to different optimal plans
- The system can observe relevant state with low cost
The following condition is typical:
This expresses that using context to decide alternate actions (, , ), after first inspecting with , can result in lower total cost than blindly executing the original path. The benefit comes from adapting to the situation, instead of using the same plan regardless of conditions.
If possible, —the task that captures runtime context—should not be part of the performance-critical sequence . Placing it outside or executing it during idle periods helps reduce overhead and avoids delaying the main task flow. This makes context-aware optimization feasible even without harming responsiveness.
4. When to Apply
At design time, a system often cannot predict all the contexts it will face at runtime. This gap between design assumptions and real-world conditions is known as the semantic gap.
To address this, the system can introduce additional mechanisms that capture runtime context as it executes. Although this adds overhead, it enables better optimization decisions that are specific to the current environment.
A well-known example is using eBPF. It helps bridge the semantic gap between user-level application behavior and kernel-level execution by allowing applications to pass contextual hints. These hints guide kernel decisions such as scheduling, filtering, or synchronization mechanism, resulting in behavior that is better aligned with the application’s intent.
5. Examples from Real Systems
| System | Description |
|---|---|
| MemLiner (OSDI’22) | Let application threads notify garbage collection tracing threads about accessed objects for better alignment of memory accesses. |
| Syrup (SOSP’21) | Use eBPF to have customized scheduling policies defined by applications. |
| CLoF (SOSP’21) | Automatically generates various hierarchical combinations of locks and selects the most performant configuration. |
Additional Notes
- Too much branching or complexity can hurt maintainability, so guardrails are important
- If the cost of collecting runtime context is too high, it can outweigh the benefit of adaptation and degrade performance
Up next: Hardware Specialization →
Hardware Specialization
Hardware specialization improves performance by deciding where a task should execute. In some cases, this means offloading work to dedicated hardware such as NICs, FPGAs, or accelerators. In other cases, the system improves efficiency by selecting the right CPU core, socket, NUMA node, or memory domain for execution.
Both strategies aim to reduce contention, latency, and resource interference by aligning each task with the most suitable hardware environment.
1. Definition with Visual Example
Specialization does not change what the task does, but optimizes how and where it is performed. This can include moving the task outside the main CPU or placing it on a more appropriate part of the CPU complex.
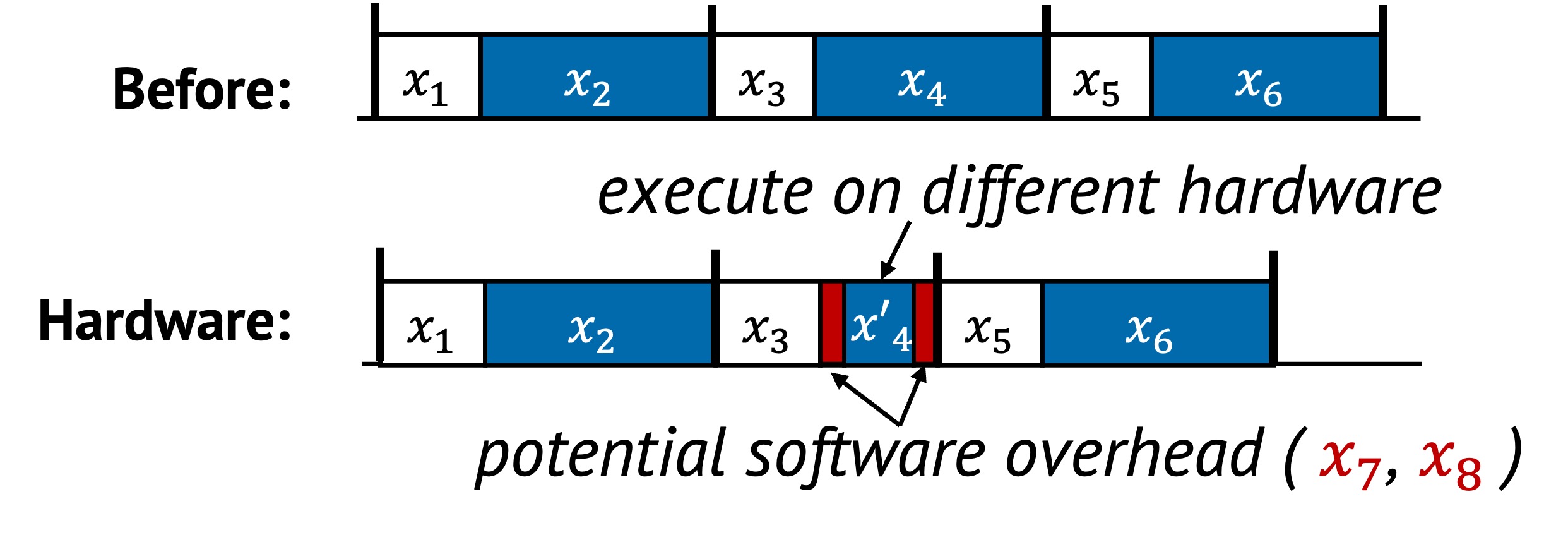
In the original sequence, all tasks to are handled uniformly by the CPU. In the optimized version, tasks is assigned to specialized hardware or localities, and executed more efficiently. Additional coordination tasks and are added to manage this transfer, such as initiating a DMA, queueing a NIC operation, or selecting the proper socket.
These changes shorten the critical path by delegating expensive or interference-prone work to better-suited components.
2. Underlying Principles
Hardware specialization typically uses:
- Replacement: Assign a task to a different hardware unit that performs the same logic more efficiently
The system leverages hardware layout, capabilities and locality to restructure execution for better efficiency.
3. Conditions for Hardware Specialization
Hardware specialization is effective when:
- A task’s cost is high on the general-purpose path
- An alternative hardware location can perform it faster or with less interference
- The overhead of setup and coordination does not outweigh the benefit
This can be described as:
Where:
- is the specialized executions of the original tasks
- and represent coordination overhead
The goal is to reduce overall cost by executing work on a more appropriate hardware resource.
4. When to Apply
There are two common strategies for hardware specialization.
Offloading to Dedicated Hardware
Tasks such as encryption, packet I/O, or compression can be moved to devices like NICs or SmartNICs, FPGAs, or accelerators. This allows the CPU to focus on serial bottlenecks while parallel or offload-friendly work is handled elsewhere.
For example:
- Packet processing can be pushed to a programmable NIC
- Storage or network checksums can be handled by an accelerator
Choosing the Right CPU Locality
Even without offloading to devices outside the CPU, choosing where a task runs within the CPU complex affects performance. Placement across CPU cores, sockets, and NUMA nodes can significantly impact access latency and resource contention.
For example:
- Assigning a thread to the same socket and core as its data reduces access delay
- Grouping cooperating threads on the same NUMA node improves memory locality
- Placing memory close to the execution core avoids unnecessary interconnect traffic
These decisions optimize performance by exploiting the system’s topology.
5. Examples from Real Systems
| System | Description |
|---|---|
| Nap (OSDI’21) | Introduce NUMA-aware layer over existing persistent memory (PM) indexes to manage hot items and avoid costly remote PM access. |
| FAERY (OSDI’22) | Adopt FPGA to accelerate embedding-based retrieval system which requires both high memory bandwidth and pipeline parallelism. |
| KV-Direct (SOSP’17) | Use programmable NICs to extend RDMA primitives and directly handle key-value operations in the host memory. |
Additional Notes
- Incorrect placement (e.g., cross-socket or oversubscribed devices) can degrade performance
- Fine-grained offloading may incur coordination costs that outweigh its benefit
Up next: Layering →
Layering
A layer is a logical division or abstraction defined during system design to organize and structure a system’s components. Each layer encapsulates a specific set of functionalities or services, helping to modularize the system and making it easier to understand, maintain, and scale. While layers provide clear structural benefits, they also introduce performance overhead, stemming from additional processing, communication, or indirection across layers.
Layering, the final methodology, optimizes sequential performance by reducing the overhead associated with layers. This methodology includes three distinct strategies:
- Bypassing: Selectively skip an entire layer.
- Delayering: Collapse or flatten layers to avoid software overhead between them.
- Decoupling: Split entangled responsibilities so they can execute independently.
1. Definition with Visual Example
Each of the three techniques is illustrated below.
Bypassing
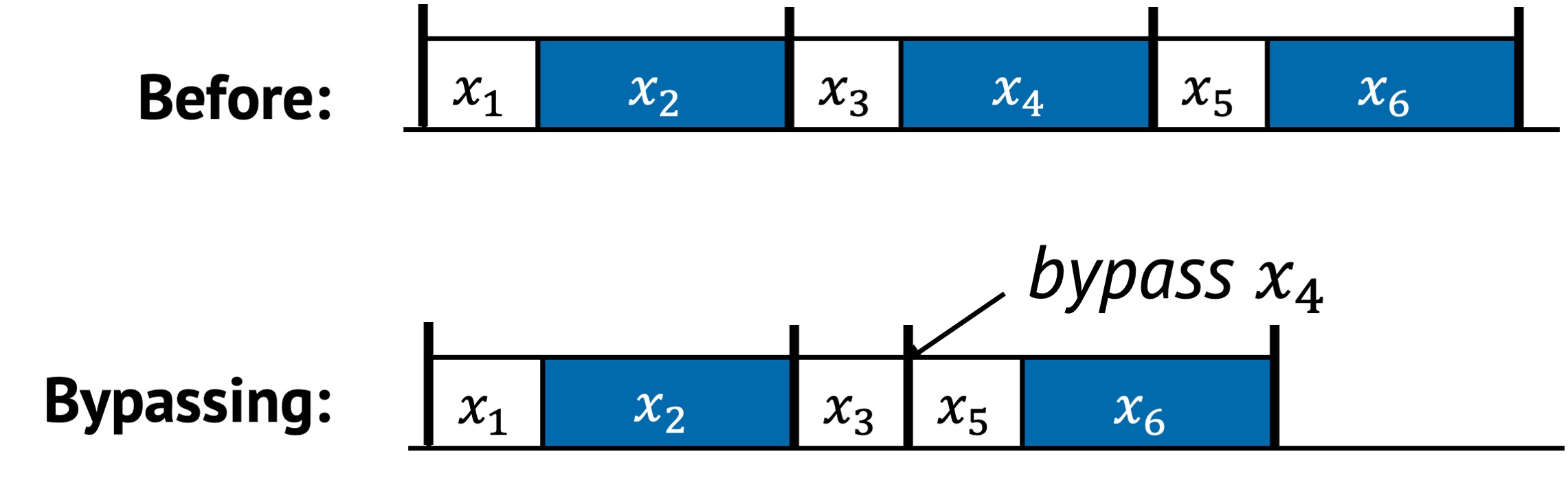
Bypassing skips intermediate layers in the system stack. In the example above, the original execution requires tasks to pass through multiple layers in a fixed sequence. After bypassing, is skipped entirely, reducing overall runtime. Bypassing is appropriate when the intermediate layer provides no essential functionality for a given workload or use case.
Delayering
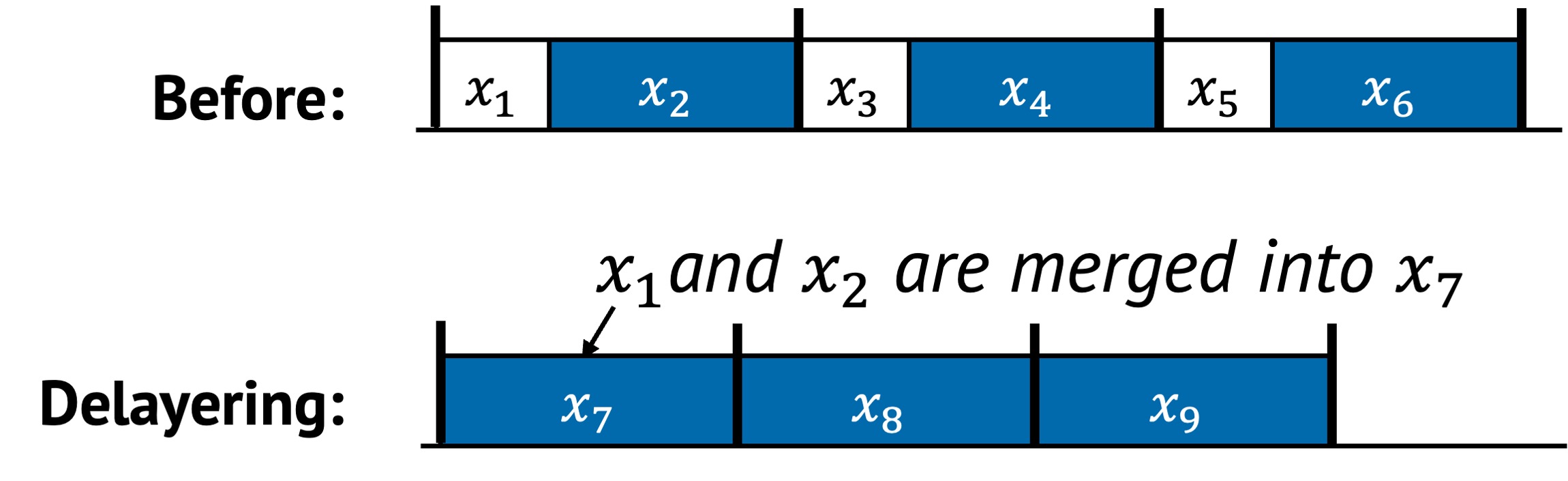
Delayering collapses multiple logically separate layers into a single composite layer. In the example above, and were originally independent layers. After delayering, they are merged into a single combined layer .
This strategy removes the overhead of calling, transitioning, or managing state between layers. It is especially useful when the boundaries exist for modularity but do not justify runtime cost.
Decoupling
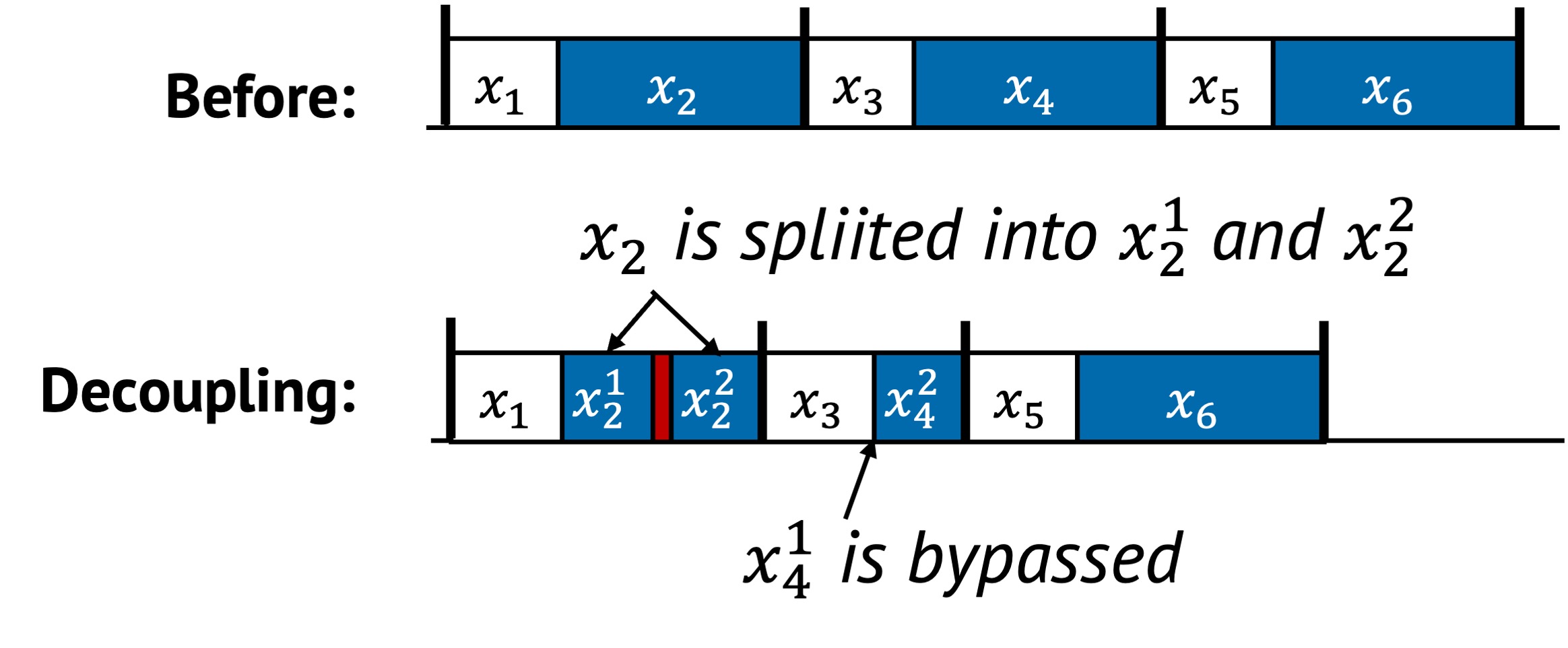
Decoupling splits a tightly bound layer into finer-grained sublayers. In the example, is decomposed into and , and into and .
- and now include some additional overhead between them, but make internal structure explicit.
- Likewise, and are fully decoupled, allowing the system to skip when it is unnecessary and run only .
This unlocks conditional execution and potential parallelism, improving flexibility and efficiency.
2. Underlying Principles
Layering uses structural change to improve efficiency, typically applying:
- Removal: Eliminates unnecessary layers or transitions across layers
- Replacement: Merge or reroute functionality through optimized paths
- Reordering:Decouple previously entangled components so they can execute independently and, if beneficial, in a different order
3. Conditions for Layering
Layering is effective when the system structure introduces avoidable overhead due to unnecessary transitions, tightly coupled responsibilities, or over-modularized logic. The following are the conditions under which each strategy applies best.
Bypassing
Bypassing is useful when layers introduce overhead without adding critical logic for a given execution path. It involves creating shortcuts or fast-paths that skip standard interfaces or kernel layers.
Common signs that bypassing may help:
- A task path repeatedly passes through a layer that does not modify or inspect the data
- Context switching between user and kernel space introduces measurable cost
- The layer enforces generic policies that do not apply in the current runtime
For example:
- Bypassing the kernel stack to handle I/O directly in user space
- User-level network stacks or storage paths that avoid VFS
- Fast-path handlers that shortcut past validation or indirection layers
- Skipping internal service layers that enforce static routing or transformation
These allow performance-critical tasks to operate with minimal indirection.
Delayering
Delayering is helpful when adjacent layers contribute to overhead through repeated validation, data marshaling, or control transitions. Rather than skipping layers, delayering merges two or more layers into one unified execution path, reducing the cost of transitions between them.
This is effective when:
- Crossing layers incurs non-trivial costs like data copying, permission checks, or synchronization
- Separate layers each add minimal logic but together cause significant cumulative delay
- Layer boundaries serve modularity or reusability, but not correctness
Delayering moves away from modularity in favor of performance. It often trades off generality, flexibility, or functionality to reduce execution time or increase throughput.
Decoupling
Decoupling applies when a single layer handles multiple roles that interfere with one another, or when unnecessary serialization exists. Splitting these responsibilities improves flexibility and can reduce overall latency.
You might apply decoupling when:
- A fast-path is blocked by slow-path operations in the same control flow
- Background tasks are serialized with latency-sensitive ones
- There are opportunities to run some parts conditionally or in parallel
For example:
- Splitting indexing from value storage in a key-value store
- Separating metadata updates from data writes so each can proceed independently
- Allowing parts of the logic (e.g., validation, logging) to be skipped when not needed
This enables a more adaptive and performant system by breaking apart tightly coupled logic.
4. Examples from Real Systems
| System | Description |
|---|---|
| nanoPU (OSDI’21) | Route incoming messages directly to the running threads’ registers, bypassing traditional memory hierarchies. |
| TinyNF (OSDI’20) | Simplify buffer management layers by removing buffer pool. Merge reception, processing and transmission into a single logical flow. |
| RackSched (OSDI’20) | Two-layer scheduling framework decouples inter-server scheduling in top-of-rack switch and intra-server scheduling in each server. |
Additional Notes
-
While both delayering and bypassing aim to reduce the number of layers being executed, their approaches differ. Delayering restructures the system architecture itself to have fewer layers, thereby simplifying the system. In contrast, bypassing selectively skips over existing layers without modifying the underlying architecture. The skipped layers remain present and may still be executed in other contexts.
-
Decoupling separates tightly integrated components into finer-grained subtasks, enhancing modularity and flexibility. This separation facilitates a more targeted optimization of individual components. Often, specialization tailored for specific hardware configurations or software requirements necessitates initial decoupling of integrated mechanisms. This ensures that modifications are minimal and do not inadvertently impact any other system components. For example, Akkio1 introduces an intermediary layer between client applications and the datastore systems to separate the allocation of shard data from its management. Consequently, this allows application to specify their own shard sizes much smaller than existing one, and determines the distribution of data across shards, facilitating customized shard assignment tailored to the needs of each application.
-
Decoupling can enable more effective caching opportunities, especially when only a subset of a task’s output is reused over time. For instance, Tsai et al. 2 first decouple permission checking from directory lookup, allowing permission results to be cached and reused independently, creating a fast path for common operations.
-
M. Annamalai, K. Ravichandran, H. Srinivas, I. Zinkovsky, L. Pan, T. Savor, D. Nagle, and M. Stumm. Sharding the Shards: Managing Datastore Locality at Scale with Akkio. In 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), pages 445–460, 2018. ISBN 978-1-939133-08-3. ↩
-
C.-C. Tsai, Y. Zhan, J. Reddy, Y. Jiao, T. Zhang, and D. E. Porter. How to get more value from your file system directory cache. In Proceedings of the 25th Symposium on Operating Systems Principles, SOSP ’15, pages 441–456, New York, NY, USA, Oct. 2015. Association for Computing Machinery. ISBN 978-1-4503-3834-9. doi: 10.1145/2815400.2815405. ↩
SysGPT
SysGPT is a language model assistant fine-tuned to suggest serial performance optimizations in system software. It encodes the eight methodologies covered in this guide and provides actionable advice tailored to specific task sequences or execution traces.
Rather than replacing domain expertise, SysGPT acts as an interactive collaborator: It helps system designers explore ideas, challenge assumptions, and identify overlooked optimization opportunities.
Motivation
Improving sequential performance often requires expert-level understanding of hardware, scheduling, caching, and software structure. However, this knowledge is often fragmented across papers, systems, and teams.
SysGPT captures the distilled methodology and applies it flexibly across domains. Given problem description and observations, it can suggest:
- Which methodology is relevant (e.g., batching, decoupling, deferring)
- What structural transformation might help
- Detailed and actionable suggestions to try
The goal is not to produce code, but to frame design decisions with methodology-aware suggestions.
Limitations
SysGPT is not a static optimizer or an automated code rewriter. It does not understand full program semantics or guarantee correctness. Its value lies in design-level feedback, not in low-level transformation.
It should be used interactively, with the user verifying or rejecting its suggestions.
Up next: How to Use →
How to use
SysGPT is a GPT-4o based model fine-tuned using OpenAI’s API. Because of the API’s usage-based pricing, we cannot make the model publicly accessible without incurring usage costs. As a result, we are unable to host or deploy it directly. Instead, we release our training data, evaluation methodology, and benchmarks used in the paper through the resources below.
Available Resources
To reproduce or experiment with SysGPT’s methodology-aware behavior, refer to the open repository:
🔗 https://github.com/sslab-gatech/SysGPT
This includes:
- The full training and test dataset used during fine-tuning
- Benchmarks and scenarios described in the paper’s evaluation
- Sample task sequences and GPT input formats
- Qualitative and quantitative evaluation results
Reproducing Results
SysGPT was evaluated in the original paper using two approaches:
-
Section 5.2 – Qualitative Measurements
Model responses were assessed for structure-awareness and alignment with the intended methodology. -
Section 5.3 – Quantitative Measurements
Suggestions were benchmarked in controlled environments to measure potential improvements in throughput and latency.
These sections can serve as a reference when applying the methodology to your own systems or when evaluating the model’s performance on new workloads.
Contributors
Here is a list of the contributors:
- Sujin Park (sujin.park@gatech.edu)
- Mingyu Guan (mingyu.guan@gatech.edu)
- Xiang Cheng (cxworks@gatech.edu)
- Taesoo Kim (taesoo@gatech.edu)
Citation
If you find our principles and methodologies useful, or have used our dataset or benchmark, please consider citing this work.
@inproceedings{park:sysgpt,
title = {{Principles and Methodologies for Serial Performance
Optimization}},
author = {Sujin Park and Mingyu Guan and Xiang Cheng and Taesoo Kim},
booktitle = {Proceedings of the 19th USENIX Symposium on Operating
Systems Design and Implementation (OSDI)},
month = jul,
year = 2025,
}